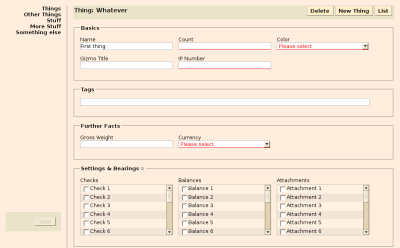
Ruby on Rails already does a good job of specifying almost declaratively what conditions objects must meet to be considered valid–that is, how they are validated.
Thus, in order to make sure that a Person’s last_name attribute does not exceed 100 characters, you would write something like this
class Person < ActiveRecord::Base
validates_length_of :last_name, :maximum => 100
end
Somewhere in a view you’ll probably refer to the last_name attribute like this
<% form_for :person, @person, :url => { :action => "update" } do |f| -%>
Last name : <%= f.text_field :last_name %>
<%= submit_tag %>
<% end -%>
There you get a nice form where users can enter last names as long as they may wish–only to be shown an error message complaining about the length in cases where they have unwittingly overshot the limit. How should they have known?
Well, as a nice and caring person you could add an annotation to each input field saying how long its contents are allowed to be. That would be slightly better, but still leaves more work for the users than necessary.
How about this: Users are immediately notified in an unobtrusive way that some of the content they have (or have not yet) filled into a form does not constitute valid data. Furthermore, users are kept from submitting a form that contains obviously invalid data.
Should be easy, shouldn’t it? Yes, it should and actually it is just two plugins away.
Raising awareness of validations
Out of the box, Rails handles validations in such a way that it adds callbacks for checking them to model classes, but otherwise immediately loses awareness of them. When later on in the lifecycle of a model instance validations are checked, Rails does so on autopilot. A model class just does it’s thing, it won’t tell you what it’s doing, but you can be sure it’ll complain when something is wrong. Let’s add some reflection to make model classes a bit more loquacious. The details are irrelevant, just install the Validation Reflection plugin into your Rails application
$ script/plugin install svn://rubyforge.org//var/svn/valirefl/validation_reflection/trunk
Tell the browser
So far, the newfound awareness of validations idles away on the server-side. Somehow it has to be transported to the user’s browser. That is one of the things the Client-Side Validation plugin does. Install with
$ script/plugin install svn://rubyforge.org//var/svn/clientsidevali/client_side_validation/trunk
The first thing this plugin does is that it enhances tags generated by Rails’s helper methods in such a way that they contain encoded information about the validation constraints that apply to their values.
Engage the client
Still, even though validation information has been inserted into the HTML sent to the browser, where it lays dormant. On the client-side, JavaScript is where the action is. Therefore the task of checking validations there is handled by a validator written in JavaScript included with the Client-Side Validation plugin.
The generic script for the validator is included in your views or layout as part of the default scripts, therefore it is probably just there already.
<%= javascript_include_tag :defaults %>
Here we come to a point where you, the programmer, have to make some decisions and do some work. First, you need to decide (or have your code decide) what locale your users are in. Remember, dates don’t look the same all over the world.
<%= javascript_include_tag 'validators-en' %>
Currently English (en) and German (de) are supported.
Then, you have to tell the validator that there’s work for it to do. For this, all forms that ought to be validated have to be marked with the class validated. Thus, the above form becomes
<% form_for :person, @person, :url => { :action => "update" }, :html => { :class => 'validated' } do |f| -%>
Last name : <%= f.text_field :last_name %>
<%= submit_tag %>
<% end -%>
Also, you need to nudge the validator to start looking at the forms by adding a line to public/javascripts/application.js
Form.Validator.installForAllValidatedForms();
You ain’t see nothing yet
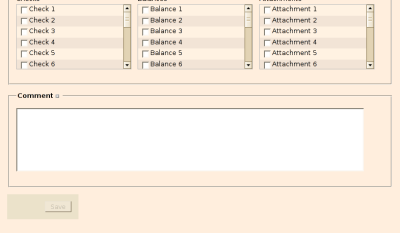
If you’ve followed all these steps, the validator is probably doing its work, but hardly see anything of it. You may notice that the submit button is enabled when the form is valid and disabled when it is invalid, but that is all there is.
A further, but still invisible, thing that the validator does is that it adds (removes) the class “invalid” to input elements when they are invalid. Making this change in attribute visible is a small matter of CSS
.invalid {
border: 1px solid #f00;
}
The result is not pretty, but you can push your stylesheeting abilities to the limit to make them look however you like. Also, the validator offers hooks for customizing most aspects. But that is left for a future installment.